Smart Search
Built a smart search system that retrieves and ranks data based on user search queries, incorporating vector-based matching, spelling correction, and optimized query execution to deliver fast and relevant results. The system is powered by Typesense for high-performance indexing, storage, and retrieval, achieving millisecond-level query latency. Designed and implemented a fully featured backend with complete API support, enabling seamless data ingestion, search, and response delivery in structured JSON format.
Problem Statement
Patching and Unpatching are a set of tools that are used for image processing. The patching tool is used to cut small square sections of the input image known as patches. The unpatching tool takes those patches and combines them back together to make the final image.
Why MongoDB Fell Short for Advanced Search

While MongoDB is a strong general-purpose document store, it shows limitations when used for advanced and large-scale search use cases, creating friction in delivering a seamless and intelligent search experience.
While MongoDB is excellent as a general-purpose document store, it becomes less effective for advanced search at scale due to limited fuzzy matching capabilities, performance bottlenecks when querying large or multi-field text datasets, and the lack of advanced tokenization, relevance scoring, and customizable ranking mechanisms, all of which negatively impact search responsiveness and result quality.
Proposed Solution
To overcome the limitations of using MongoDB for advanced search, the system architecture was enhanced by introducing a dedicated search engine layer.
To address the identified search challenges, the search layer was decoupled from the storage layer by introducing Typesense, a fast, in-memory search engine designed for instant and typo-tolerant search; MongoDB continues to serve as the primary persistence layer for application data, while Typesense functions as a read-optimized indexing layer that stores only searchable fields—during a search request, the user submits a query, Typesense retrieves the most relevant document IDs from its index, and those IDs are then used to fetch the complete document details from MongoDB.
Why Typesense Over Alternatives?

Multiple search solutions were evaluated before selecting Typesense as the dedicated search engine for the system.
Several search engines were evaluated, including Elasticsearch, MeiliSearch, and MongoDB Atlas Search, but Typesense emerged as the best fit due to its lightning-fast, in-memory performance with millisecond-level query latency, configurable typo tolerance and fuzzy search capabilities, seamless MongoDB integration via a reliable Python connector, fully open-source and transparent licensing, and a rich developer experience with a clean RESTful API, dynamic schemas, and real-time indexing support.
Implementation Highlights
The search system was implemented incrementally with minimal disruption to the existing MongoDB-based architecture by introducing a dedicated, read-optimized search layer.
The implementation followed a multi-stage, incremental approach designed to enhance search capabilities without disrupting the existing MongoDB-centric system, guided by the principle of decoupling search and storage layers; during architectural planning, minimal and non-invasive changes were identified to preserve MongoDB as the primary persistence layer while introducing a parallel, read-optimized Typesense layer, where MongoDB continues to manage persistent data storage and Typesense indexes only the necessary searchable content to deliver fast, fuzzy, and typo-tolerant search queries.
Typesense Integration and Deployment
Typesense was deployed using a containerized approach to ensure portability, scalability, and clean separation from the core application runtime.
Typesense was integrated and deployed using a Docker-based containerized setup, enabling rapid provisioning of both local and cloud-based instances with minimal configuration; this approach provides easy lifecycle management and redeployment, ensures service isolation from the main application runtime, and allows independent horizontal scaling of the search layer without impacting the core database or application services.
Data Ingestion Workflow
A controlled data ingestion strategy was implemented to ensure Typesense always had access to accurate and up-to-date searchable content from MongoDB.
To keep Typesense synchronized with MongoDB while minimizing system complexity, a manual ingestion workflow was chosen due to the relatively static nature of the dataset; data is first ingested into MongoDB as the source of truth, a custom ingestion script then reads the documents, formats and pushes only the relevant searchable fields into Typesense while preserving the MongoDB _id for lookup, and during search operations Typesense returns matching document IDs that are subsequently used to fetch the complete documents from MongoDB.
Search Optimization
Advanced search optimization techniques were applied to fully leverage Typesense’s high-performance and configurable search capabilities.
Search optimization was implemented iteratively to maximize relevance, speed, and user experience by leveraging Typesense’s configurable search engine; fuzzy matching was enabled using configurable num_typos to tolerate common misspellings and input errors, significantly improving usability in free-form and mobile searches, while automatic tokenization and prefix matching allowed multi-word, partial-word, and autocomplete-style queries with proper handling of stop words and disjointed keywords; although not part of the initial release, synonyms and word replacement support were evaluated for future enhancements such as domain-specific term mapping and pluralization handling; each optimization underwent manual relevance testing, latency benchmarking, and iterative tuning of parameters like query_by_weights, typo tolerance, and prefix settings until the optimal balance between performance, relevance, and fault tolerance was achieved and deployed to production.
API Integration
The search API was refactored to leverage Typesense for fast query execution while preserving MongoDB as the system of record.
The application’s search API endpoint was updated to query Typesense instead of MongoDB, returning a ranked list of matching document IDs that are subsequently used to fetch full records from MongoDB; this approach significantly improves search performance, preserves data consistency by keeping MongoDB as the source of truth, and ensures the frontend and client experience remains unchanged, with the optimization isolated entirely within the backend request flow.
Outcome
The hybrid architecture delivers fast, typo-tolerant search through Typesense while maintaining reliable and consistent data retrieval from MongoDB, with a modular and scalable design.
With this hybrid setup, the system benefits from fast, responsive, typo-tolerant search via Typesense, reliable and consistent data retrieval from MongoDB, and a flexible, modular architecture that is easy to scale; this solution balances performance and maintainability, allowing the search experience to evolve without compromising core data integrity.
+-------------+ Search Query +--------------+
| | -----------------------------> | |
| Frontend | | Typesense |
| Client | <----------------------------- | Search API |
| | Result: IDs | |
+-------------+ +--------------+
|
| fetch by ID
v
+--------------+
| |
| MongoDB |
| Database |
+--------------+
Conclusion & Results
Integrating Typesense alongside MongoDB enhanced search performance, relevance, and scalability without requiring a major overhaul of existing infrastructure.
By integrating Typesense as a dedicated search engine alongside MongoDB, the system achieved a hybrid architecture that combines robust, flexible data storage with a fast, intelligent search layer, providing a solid foundation for future growth. The results and impact include: performance boost with search latency often under 50ms, improved user experience with typo-tolerant, forgiving search queries, and scalability through a decoupled architecture that allows MongoDB to handle data durability while Typesense ensures fast, reliable retrieval.
Explore More
Built a smart search system that retrieves and ranks data based on user search queries, incorporating vector-based matching, spelling correction, and optimized query execution to deliver fast and relevant results. The system is powered by Typesense for high-performance indexing, storage, and retrieval, achieving millisecond-level query latency. Designed and implemented a fully featured backend with complete API support, enabling seamless data ingestion, search, and response delivery in structured JSON format.
Patching and Unpatching are a set of tools that are used for image processing. The patching tool is used to cut small square sections of the input image known as patches. The unpatching tool takes those patches and combines them back together to make the final image.
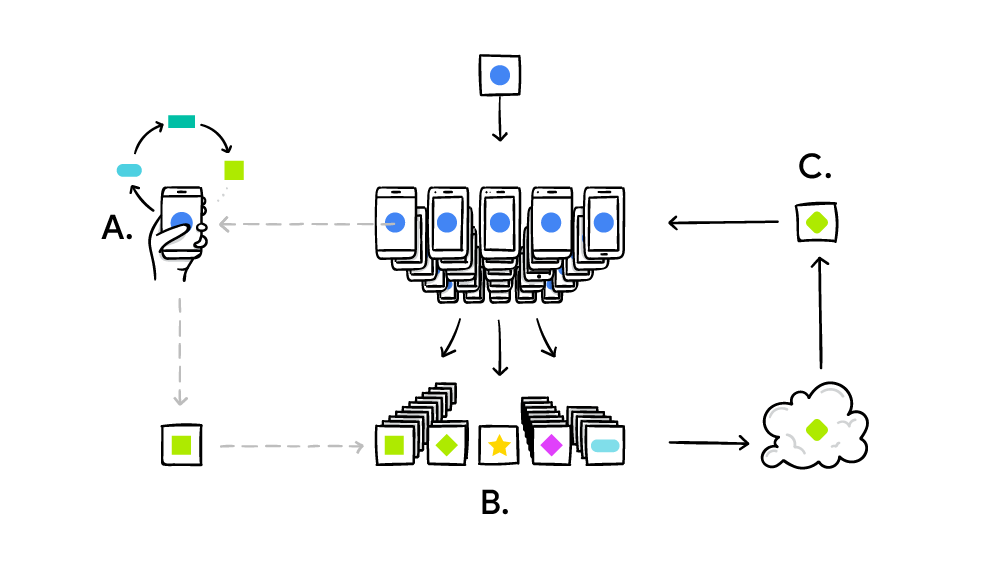
Patching and Unpatching are a set of tools that are used for image processing. The patching tool is used to cut small square sections of the input image known as patches. The unpatching tool takes those patches and combines them back together to make the final image.
The Tiny-URL Generator is a URL shortening service developed as a web application using the Flask framework. This project aims to simplify the process of sharing long URLs by generating shorter, more manageable links. The backend leverages Redis for efficient data storage and retrieval, ensuring quick access and collision-free management of shortened URLs.

Patching and Unpatching are a set of tools that are used for image processing. The patching tool is used to cut small square sections of the input image known as patches. The unpatching tool takes those patches and combines them back together to make the final image.
Static Academic website made to showcase the profile and works, made using HTML, CSS, Media Query (for the responsive optimization for mobile, tablet and different size devices). The website is consist of 8 pages that shows the different aspects from main page to contact page. Google Maps API is used to display the map. CSS flex boxes are also used for more size responsive optmizatrions
Federated Learning is a decentralized learning paradigm where models are trained on various devices, and their parameters are combined to create a global model. Initially introduced by Google in 2017, it allows for effective model training without transferring sensitive data from devices

The neural style transfer is implemented as per paper that came in 2015 title A Neural Algorithm of Artistic Style. The paper talks about combing the two images to create a new style image by using the style and feature transfer technique from both the images and tries to minimize the loss of the generated Gaussian image by using the custom loss function that can be tweaked by using the hyper-parameter alpha and beta. The implementation is done using pytorch
Real-time communication systems are deceptively complex. What starts as a simple “send and receive messages” problem quickly expands into challenges around scalability, data consistency, authentication, latency, and fault tolerance. In this article, we will walk through how I designed and built a production-ready, real-time chat application, covering architectural decisions, backend and frontend design, and the technology stack used.