Federated Learning
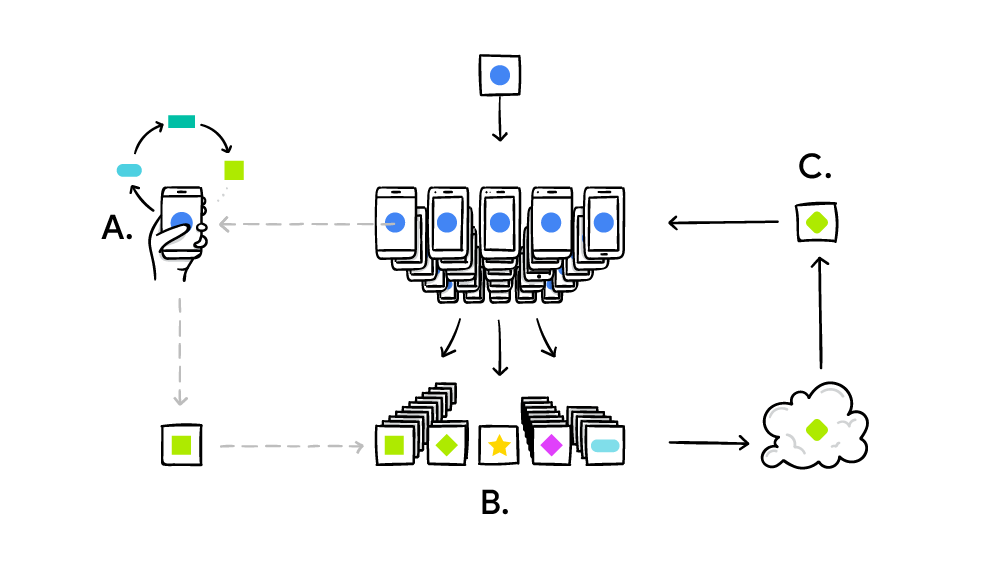
Federated Learning is a decentralized learning paradigm where models are trained on various devices, and their parameters are combined to create a global model. Initially introduced by Google in 2017, it allows for effective model training without transferring sensitive data from devices.
Federated Average Algorithm
The Federated Average Algorithm is a key component of Federated Learning, facilitating the aggregation of locally trained model parameters from multiple devices or workers into a global model. Here's a more detailed explanation of how the Federated Average Algorithm works:
1. Initialization:
- Initially, a global model with its parameters is defined. This model is typically a neural network architecture tailored for the specific task at hand (e.g., image classification, natural language processing).
- Each participating device or worker initializes its local model with the same parameters as the global model.
2. Local Model Training:
- Each device or worker trains its local model using its own local dataset. This training process is typically performed using standard optimization techniques such as stochastic gradient descent (SGD) or its variants.
- During training, the local model parameters are updated based on the gradients computed from the local dataset.
3. Model Parameter Aggregation:
- Once local training is complete, the updated parameters of each local model are communicated back to the central server or aggregator (often referred to as the federated server).
- The federated server collects the parameters from all participating devices.
4. Federated Averaging:
- The federated server performs aggregation, usually through simple averaging, to compute a new set of global model parameters.
- This aggregation process combines the parameters from all participating devices to generate a more robust and generalized global model.
5. Distribution of Global Model:
- The updated global model parameters are then distributed back to all participating devices.
- This updated global model serves as the basis for the next round of local model training.
Iterative Process:
- The entire process repeats iteratively over multiple rounds.
- With each round, the global model tends to improve as it incorporates insights from diverse data sources and learns from different device-specific patterns.
Advantages of Federated Average Algorithm:
- Privacy Preservation: Since raw data remains on the local devices and only model parameters are exchanged, federated learning preserves user privacy and data security.
- Decentralization: Federated learning enables distributed model training across devices, reducing the need for centralized data storage and processing.
- Scalability: It can scale to a large number of devices, making it suitable for applications with massive user bases.
Challenges and Considerations:
- Communication Overhead: Communication between devices and the central server introduces latency and bandwidth constraints.
- Heterogeneity: Devices may have varying computational capabilities, network conditions, and data distributions, necessitating techniques to handle heterogeneity.
- Model Drift: As devices update the global model based on their local data, there is a risk of model drift, where the global model may diverge from the optimal solution due to variations in local datasets.
- Security Concerns: Federated learning introduces new security risks, such as model poisoning attacks and privacy breaches, which need to be addressed through robust security measures. Overall, the Federated Average Algorithm forms the backbone of Federated Learning, enabling collaborative model training across distributed devices while preserving privacy and scalability.
The Experiment -
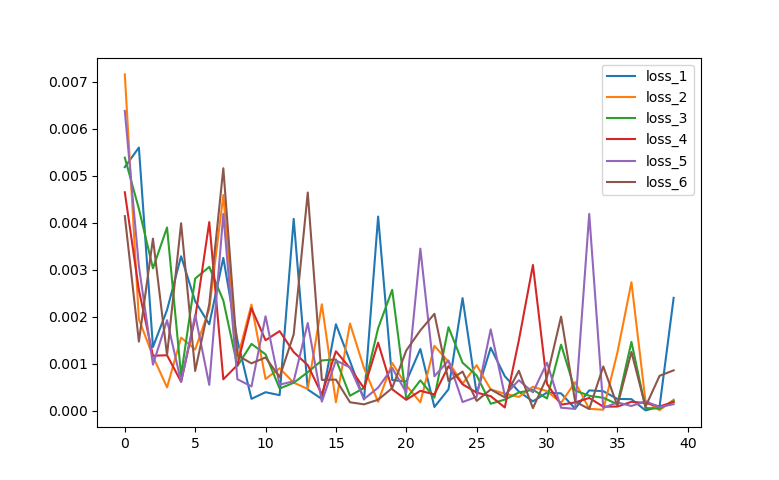
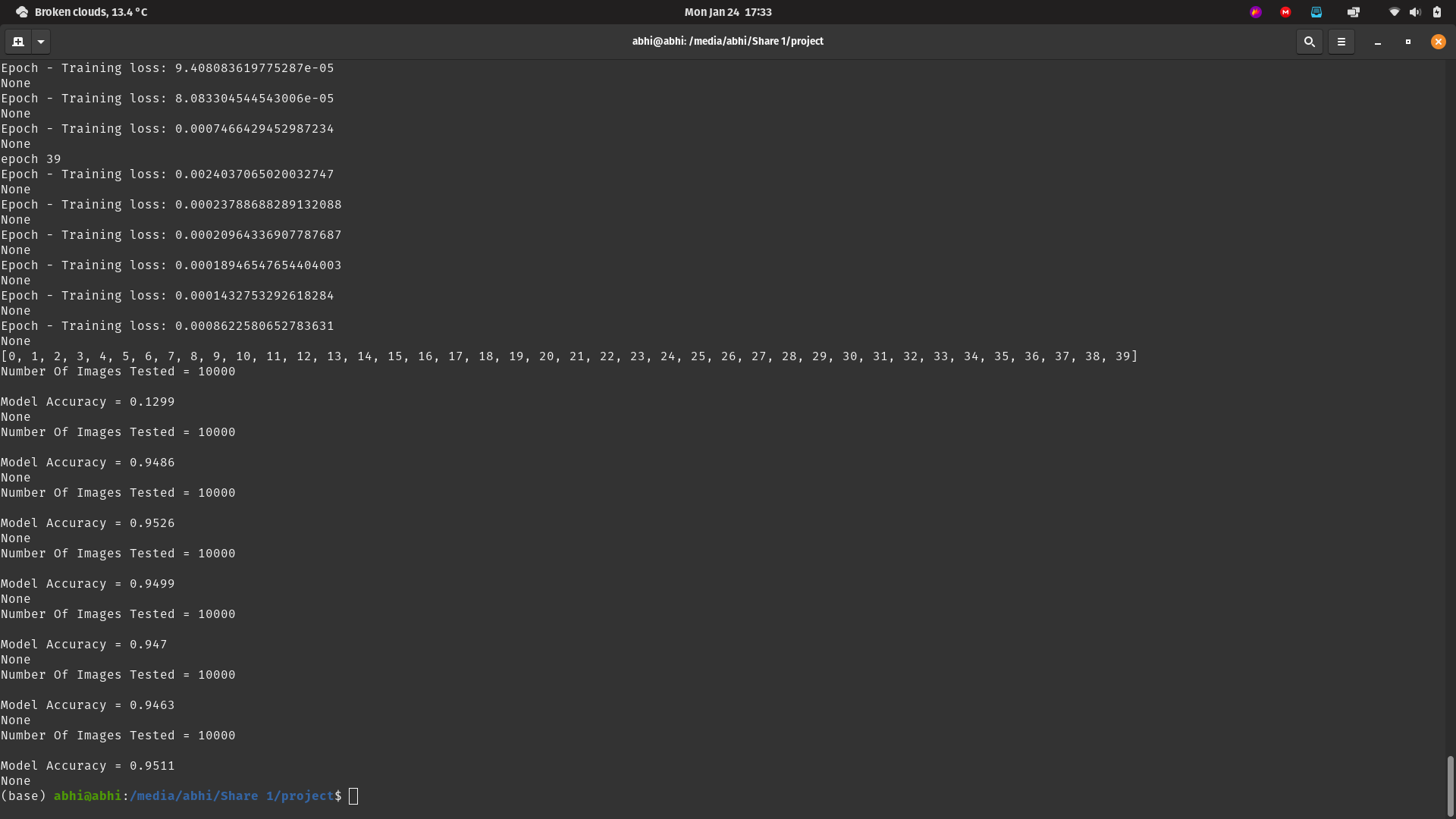
In this program I have implement 6 workers (virtual devices) that take the MNIST data and train on 10000 data points one each. The Global model is made using the Fed-Avg Algo that is used for the aggregation of the parameters.
Algo description -
- Since the parameters of the main model and parameters of all local models in the nodes are randomly initialized, all these parameters will be different from each other. For this reason, the main model sends its parameters to the nodes before the training of local models in the nodes begins.
- Nodes start to train their local models over their own data by using these parameters.
- Each node updates its parameters while training its own model. After the training process is completed, each node sends its parameters to the main model.
- The main model takes the average of these parameters and sets them as its new weight parameters and passes them back to the nodes for the next iteration.
Model Training
Results
- Graph to showing accuracy of the 6 worker models in test set.
Explore More
Built a smart search system that retrieves and ranks data based on user search queries, incorporating vector-based matching, spelling correction, and optimized query execution to deliver fast and relevant results. The system is powered by Typesense for high-performance indexing, storage, and retrieval, achieving millisecond-level query latency. Designed and implemented a fully featured backend with complete API support, enabling seamless data ingestion, search, and response delivery in structured JSON format.
Patching and Unpatching are a set of tools that are used for image processing. The patching tool is used to cut small square sections of the input image known as patches. The unpatching tool takes those patches and combines them back together to make the final image.
Patching and Unpatching are a set of tools that are used for image processing. The patching tool is used to cut small square sections of the input image known as patches. The unpatching tool takes those patches and combines them back together to make the final image.
The Tiny-URL Generator is a URL shortening service developed as a web application using the Flask framework. This project aims to simplify the process of sharing long URLs by generating shorter, more manageable links. The backend leverages Redis for efficient data storage and retrieval, ensuring quick access and collision-free management of shortened URLs.

Patching and Unpatching are a set of tools that are used for image processing. The patching tool is used to cut small square sections of the input image known as patches. The unpatching tool takes those patches and combines them back together to make the final image.
Static Academic website made to showcase the profile and works, made using HTML, CSS, Media Query (for the responsive optimization for mobile, tablet and different size devices). The website is consist of 8 pages that shows the different aspects from main page to contact page. Google Maps API is used to display the map. CSS flex boxes are also used for more size responsive optmizatrions
Federated Learning is a decentralized learning paradigm where models are trained on various devices, and their parameters are combined to create a global model. Initially introduced by Google in 2017, it allows for effective model training without transferring sensitive data from devices

The neural style transfer is implemented as per paper that came in 2015 title A Neural Algorithm of Artistic Style. The paper talks about combing the two images to create a new style image by using the style and feature transfer technique from both the images and tries to minimize the loss of the generated Gaussian image by using the custom loss function that can be tweaked by using the hyper-parameter alpha and beta. The implementation is done using pytorch
Real-time communication systems are deceptively complex. What starts as a simple “send and receive messages” problem quickly expands into challenges around scalability, data consistency, authentication, latency, and fault tolerance. In this article, we will walk through how I designed and built a production-ready, real-time chat application, covering architectural decisions, backend and frontend design, and the technology stack used.